2) Design Documentation - snuhcs-course/swpp-2025-project-team-03 GitHub Wiki
- 1. Document Revision History
- 2. System Design
- 3. Implementation Details
- 4. AI Feature Pipeline
- 5. Testing Plan (Iteration 4+)
- 6. External Libraries
- 7. Risk Management & Mitigation
- 8. Glossary & References
- 9. Dataset & Research
| Version | Date | Message |
|---|---|---|
| 0.1 | 2025-10-02 | Initial draft created |
| 1.1 | 2025-10-14 | Update API specification |
| 1.2 | 2025-10-14 | Add Table of Contents |
| 1.3 | 2025-10-16 | Update Testing Plan & ERD |
| 1.4 | 2025-10-16 | Update Frontend class diagram |
| 2.1 | 2025-10-23 | Update Testing Plan |
| 2.2 | 2025-10-30 | Update API specification(ver.2) |
| 2.3 | 2025-10-30 | Update ERD & Data models |
| 2.4 | 2025-10-30 | Update architecture diagram |
| 2.5 | 2025-11-01 | Update Iter3 final ERD & API specification(ver.2) |
| 2.6 | 2025-11-02 | Update Testing Plan & Results |
| 3.1 | 2025-11-09 | Added detailed architecture, data flow, and DevOps specifications |
| 3.2 | 2025-11-11 | Added Testing Plan |
| 3.3 | 2025-11-15 | Added Risk Mitigation & Update Architecture, ERD, WireFrame |
| 4.1 | 2025-11-16 | Update Testing Plan |
| 4.2 | 2025-11-20 | Update system architecture description & typo |
| 4.3 | 2025-11-26 | Update ERD & API Overview |
| 4.4 | 2025-11-29 | Added AI Feature Pipeline |
| 4.5 | 2025-11-30 | Restructure AI Feature Pipeline & update test results |
- Frontend: Android (Jetpack Compose + Retrofit + Hilt DI)
- Backend: Django REST Framework (team3 server)
- Database: PostgreSQL (team3 server)
- Storage: AWS S3 bucket
- AI Integration: OpenAI GPT-4o/GPT-4o-mini, Google Cloud Speech-to-Text API
- Pattern: Client-Server architecture with RESTful API integration and JWT authentication
- Environments: Backend server running on a single Linux machine using Gunicorn (15 workers, 4 threads per worker; max 60 concurrent requests), with PostgreSQL database hosted on the same machine, one AWS S3 bucket.
- Network: Application and database run in the same private network/VPC; ingress handled directly by Gunicorn behind Nginx.
-
Secrets Management: Environment variables via
.env; migration to a managed secrets store is on the roadmap. - CI/CD: GitHub Actions handles format checks and automatically triggers deployments; server code is updated over SSH/rsync and the backend is restarted.
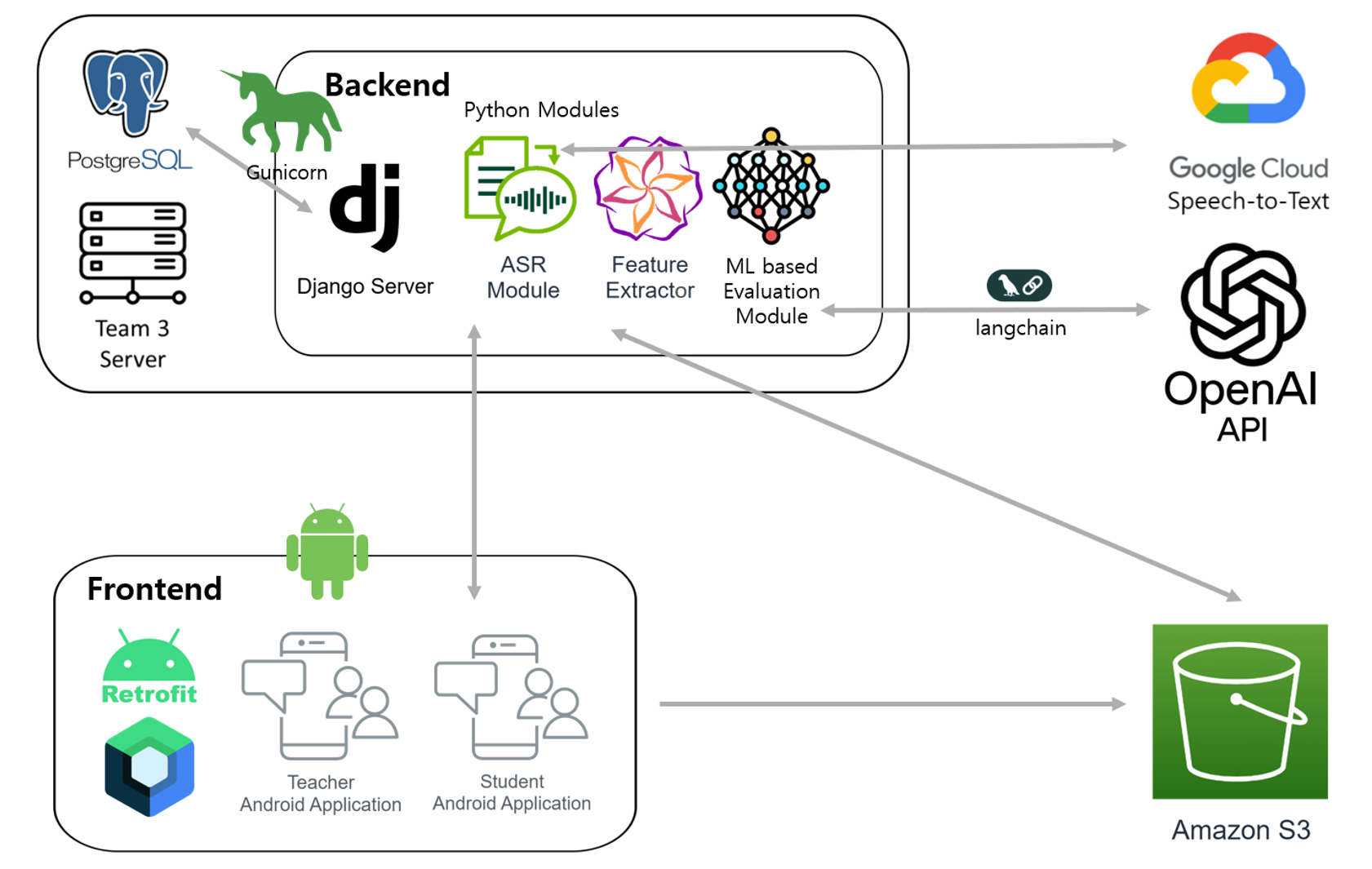
| Layer | Component | Responsibility | Tech Stack | Observability |
|---|---|---|---|---|
| Presentation | Android App (Jetpack Compose) | Render dashboards, microphone capture, file management | Kotlin, Jetpack Compose, Hilt, Retrofit | Standard Android logging |
| API Gateway | Nginx + Gunicorn | TLS termination, reverse proxy, static asset serving | Nginx, Gunicorn (15 workers, 4 threads/worker) | Nginx access logs, Django request logging |
| Application | Django services (accounts, courses, assignments, questions, reports, submissions, etc) |
Role-based access control, AI pipeline orchestration (external APIs, PyTorch inference), and quiz lifecycle automation from parsed PDFs | Python 3.12, Django REST Framework | Django logging, health-check endpoints |
| Data | PostgreSQL 15 | Persist transactional data (assignments, enrollments, submissions, etc) with timezone-aware timestamps | PostgreSQL, psycopg3 | pg_stat_statements, slow-query logging |
| AI Worker (External) | In-process external API calls (synchronous) | STT processing, prompt generation, semantic evaluation, tail-question generation executed inside request cycle | LangChain, LangGraph, OpenAI GPT-4o/GPT-4o-mini, Google Cloud Speech-to-Text | Django application logging, API latency tracking |
| ML Worker (Internal) | In-process model inference (synchronous) | Confidence scoring via XGBoost regression on acoustic and semantic features extracted from student responses | XGBoost 3.0.5, joblib, scikit-learn | Django application logging, inference latency tracking |
| Storage | AWS S3 | Store PDFs, assets, etc | S3 Intelligent-Tiering, presigned URLs | S3 object access logs, lifecycle policies |
- Teacher uploads PDF: File stored in S3 via presigned URL → Django backend extracts text using PyMuPDF → text chunks sent to GPT-4o for question generation → questions saved in database and associated with assignment.
-
Students launch quiz: Android app fetches assignment metadata and personal assignment questions via
/personal_assignments/{id}/questions/→ UI displays questions sequentially. -
Student records response: Audio recorded on device → uploaded as multipart/form-data to
/personal_assignments/answer/→ backend runs Google Cloud STT → extracts acoustic and semantic features → XGBoost model predicts confidence score → GPT evaluates correctness → tail question generated via LangGraph if needed. -
Results storage: Submission saved with
text_answer,state,eval_grade,started_at,submitted_at→ personal assignment status updated to reflect progress. -
Teacher dashboards: Query aggregated statistics on demand via Django ORM (no materialized views); endpoints include
/assignments/teacher-dashboard-stats/,/courses/classes/{id}/students-statistics/,/reports/{class_id}/{student_id}/for curriculum analysis.
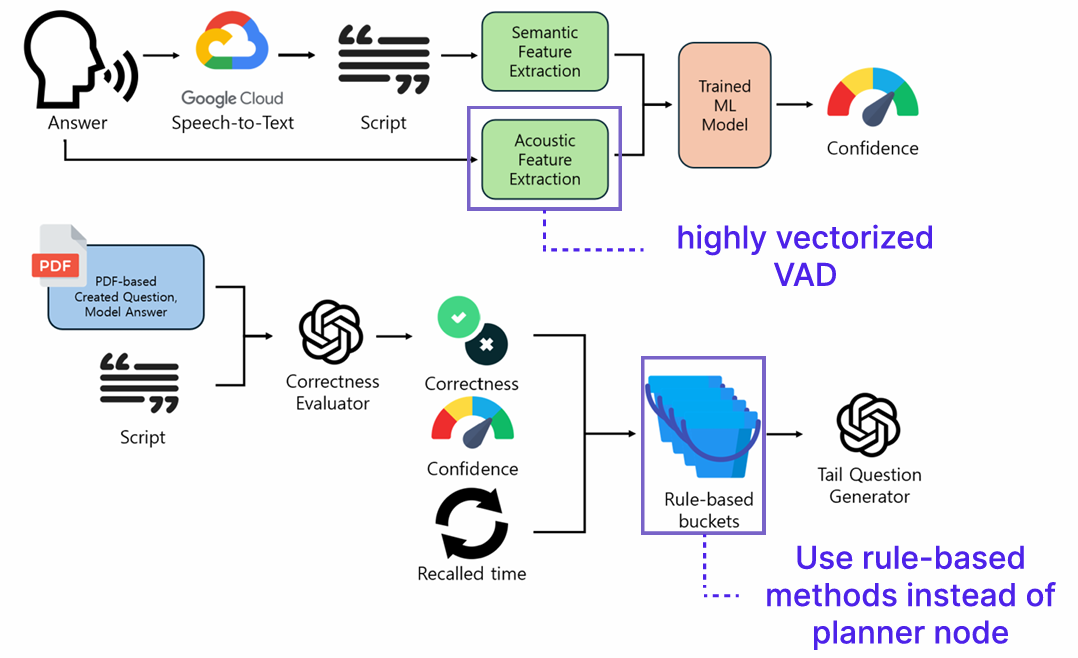
-
Feature Extraction (
extract_all_features): Runs Google STT, prosodic analysis (extract_acoustic_features), and semantic coherence metrics (extract_features_from_script). Acoustic cues (pause ratios, f0 slope, silence %) and semantic embeddings feed downstream models, embodying Hasan et al.’s affect perception requirements. -
Confidence Inference (
run_inference): XGBoost regression produces a continuous certainty score (1–8) and letter grade from the multimodal feature vector, following Pelánek & Jarušek’s guidance to combine behavioral and linguistic signals. -
Semantic Planner (
planner_node): A temperature-0 GPT-4o-mini call with minimal JSON prompt returns{"is_correct": true|false}based solely on meaning equivalence between model answer and transcript, tolerant of ASR artifacts. -
Rule-based Routing (
decide_bucket_confidence): Correctness × confidence yields buckets A–D with configurable high/low threshold (default 3.45). This enforces the four-quadrant scaffold aligned with Abar et al.’s ZPD scaffolding findings. -
Strategy Selection (
decide_plan): Adjusts follow-up frequency by bucket andrecalled_time; high-performing learners can graduate to correctness-only responses after repeat success. -
Tail Question Actor (
actor_node): Bucket-specific strategy strings plus few-shot exemplars guide GPT to emit concise Korean JSON payloads (topic, question, model answer, explanation, difficulty). Sanitizers enforce JSON validity and strip LaTeX/backslash artifacts for real-time use. -
State Graph Orchestration (
langgraph.StateGraph): Planner → derive → actor/only_correct nodes compiled once and invoked viagenerate_tail_question(), enabling deterministic flows and granular unit tests.
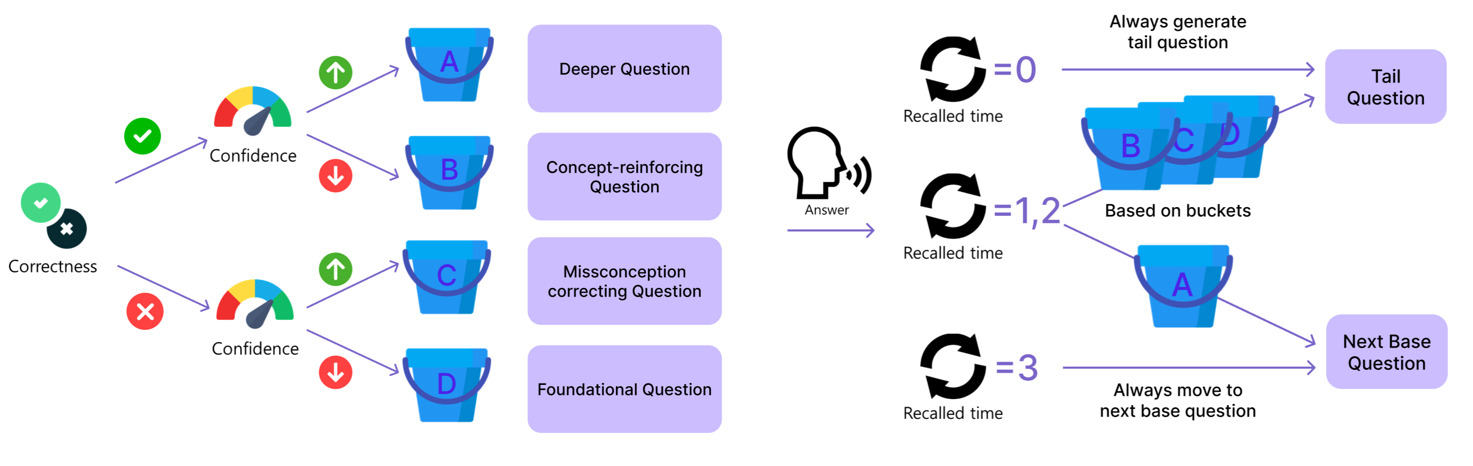
| Bucket | Planner Verdict | Confidence Range | Strategy Focus | Actor Difficulty |
|---|---|---|---|---|
| A | Correct | ≥ high_thr | Enrichment / cross-concept transfer | hard |
| B | Correct | < high_thr | Reinforcement & confidence building | medium |
| C | Incorrect | ≥ high_thr | Misconception diagnosis & correction | medium |
| D | Incorrect | < high_thr | Foundational scaffolding & guided recall | easy |
- OpenAI: GPT-4o-mini/gpt-4o for quiz generation, scoring rubric alignment, and tail question creation; invoked synchronously per answer submission.
-
Google Cloud STT: Speech-to-text transcription (16kHz mono) for uploaded WAV files using the
latest_longmodel with word confidence. - AWS S3: Storage for assignment materials and audio artifacts via presigned URL uploads/checks.



























The diagram above illustrates an Entity Relationship Diagram (ERD) outlining the Django models for our tutoring and AI quiz service. Each entity corresponds to a key feature in the platform, and the relationships define how classes, assignments, and personalized learning are connected.
Accounts are distinguished by role (student or teacher), and students register for classes through enrollments. Each class contains a foreign key to the subject, and assignments are created under these classes with structured deadlines and question sets. Materials such as PDFs can be attached to assignments for learning support.
Students receive personalized assignments that track progress and completion, while individual questions include explanations and model answers. Answers are stored with correctness and grading information, enabling both automatic evaluation and tail questions. Overall, this schema supports personalized learning by enabling classroom management, customized tasks, AI-based scoring, and continuous feedback.
| Table | Purpose | Key Columns | Notes |
|---|---|---|---|
accounts_user |
Stores teacher & student identities |
id, email, role, display_name, locale, is_active
|
Email unique; soft-delete tracked via is_active
|
courses_courseclass |
Represents a class/cohort |
id, teacher_id, subject_id, name, description, created_at
|
Student count computed via ORM (no stored trigger) |
assignments_assignment |
Assignment metadata |
id, course_class_id, subject_id, title, description, total_questions, due_at, grade, created_at
|
S3 materials stored via related assignments_material
|
questions_question |
Canonical question bank entry |
id, assignment_id, content, answer, difficulty, curriculum_code
|
Supports multilingual content using translation table |
personal_assignments_personalassignment |
Assignment per student |
id, assignment_id, student_id, status, solved_num, started_at, submitted_at, created_at
|
Unique constraint (student, assignment) |
submissions_submission |
Individual answer attempt (Answer model) |
id, question_id, student_id, text_answer, state, eval_grade, started_at, submitted_at, created_at
|
Correctness + confidence stored on each answer |
Reports are generated on demand via
reports.utils.analyze_achievement.parse_curriculum. The module identifies a student’s weaknesses by mapping their performance to the Korean curriculum achievement standards.
Currently there is no external event bus. Key state transitions occur inside the API layer:
-
AssignmentPublished: creates personal assignments for enrolled students and issues S3 upload keys. -
SubmissionEvaluated: updates personal-assignment status and creates tail questions when needed. -
ReportRequested: invokes curriculum analysis synchronously and returns the response.
All endpoints are served under /api/ and return the standard envelope { "success": bool, "data": any, "message": str | null, "error": str | null }. Detailed API documentation and test interface are available at /swagger/.
Core
| Method | Path | Description |
|---|---|---|
| GET | /core/health/ |
Health check endpoint |
| GET | /core/error/ |
Intentionally raises an error (debug/testing) |
| GET | /core/logs/tail |
Return the last n lines of nohup.out (n query param required) |
Authentication
| Method | Path | Description |
|---|---|---|
| POST | /auth/signup/ |
Create teacher/student account and issue JWT pair |
| POST | /auth/login/ |
Authenticate and obtain JWT pair |
| POST | /auth/logout/ |
Client-initiated logout (stateless) |
| DELETE | /auth/account/ |
Delete user account and all associated data |
Assignments
| Method | Path | Description |
|---|---|---|
| GET | /assignments/ |
List assignments (teacherId, classId, status filters) |
| POST | /assignments/create/ |
Create assignment and return S3 presigned upload URL |
| GET | /assignments/{id}/ |
Retrieve assignment detail (materials included) |
| PUT | /assignments/{id}/ |
Update assignment metadata |
| DELETE | /assignments/{id}/ |
Delete assignment |
| POST | /assignments/{id}/submit/ |
Placeholder endpoint for manual submission workflow |
| GET | /assignments/{id}/questions/ |
List generated/base questions |
| GET | /assignments/{id}/results/ |
Completion summary for personal assignments |
| GET | /assignments/{assignment_id}/s3-check/ |
Validate uploaded PDF in S3 |
| GET | /assignments/teacher-dashboard-stats/ |
Aggregate counts for teacher dashboard |
Questions
| Method | Path | Description |
|---|---|---|
| POST | /questions/create/ |
Generate base questions/summary from uploaded material |
Courses – Students
| Method | Path | Description |
|---|---|---|
| GET | /courses/students/ |
List students (filter by teacherId/classId) |
| GET | /courses/students/{id}/ |
Student profile with enrolments |
| PUT | /courses/students/{id}/ |
Update student fields |
| GET | /courses/students/{id}/classes/ |
List classes that the student is enrolled in |
Courses – Classes
| Method | Path | Description |
|---|---|---|
| GET | /courses/classes/ |
List classes (optional teacherId) |
| POST | /courses/classes/ |
Create class |
| GET | /courses/classes/{id}/ |
Class detail |
| PUT | /courses/classes/{id}/ |
Update class metadata |
| DELETE | /courses/classes/{id}/ |
Delete class |
| GET | /courses/classes/{id}/students/ |
List enrolled students |
| PUT | /courses/classes/{id}/students/ |
Enrol student via id/name/email |
| GET | /courses/classes/{classId}/students-statistics/ |
Per-student completion stats |
| DELETE | /courses/classes/{classId}/student/{studentId} |
Remove student from class |
Personal Assignments & Submissions
| Method | Path | Description |
|---|---|---|
| GET | /personal_assignments/ |
List personal assignments (student_id or assignment_id required) |
| GET | /personal_assignments/{id}/questions/ |
Base + tail questions for personal assignment |
| GET | /personal_assignments/{id}/statistics/ |
Aggregated stats |
| POST | /personal_assignments/{id}/complete/ |
Mark as submitted |
| POST | /personal_assignments/answer/ |
Upload WAV answer (multipart) |
| GET | /personal_assignments/answer/ |
Fetch next question (personal_assignment_id query) |
| GET | /personal_assignments/{id}/correctness/ |
List answered questions with correctness |
| GET | /personal_assignments/recentanswer/ |
Most recent in-progress assignment for student |
Reports & Catalog
| Method | Path | Description |
|---|---|---|
| GET | /reports/{class_id}/{student_id}/ |
Curriculum analysis report generated on demand |
| GET | /catalog/subjects/ |
List available subjects |
- Feature extraction (
submissions/utils/feature_extractor/\*) converts audio to transcripts plus acoustic/semantic features. - Confidence scoring (
submissions/utils/inference.py) uses XGBoost to predict certainty. - Tail-question generation (
submissions/utils/tail_question_generator/generate_questions_routed.py) routes planner verdicts through bucket strategies with LangGraph + GPT-4o-mini. -
submissions/views.AnswerSubmitVieworchestrates the flow synchronously; tests mock STT/LLM for deterministic coverage.
-
Layering: MVVM with
ViewModelmediating between UI Composables and repository layer. Repository abstracts Retrofit services and handles API communication. -
Navigation:
NavHostwith composable-based navigation for student and teacher flows; route-based navigation with parameters. -
State Handling:
StateFlowandMutableStateFlowfor reactive state management; ComposerememberSaveablepreserves quiz progress through configuration changes. -
Offline Strategy:
OfflineManagerclass implemented with file-based caching and pending action queue. -
Dependency Injection: Hilt modules for API clients, repositories, ViewModels. Testing uses
@HiltAndroidTestwith customHiltTestRunnerandFakeApiServicefor deterministic tests. -
File Management:
FileManagerhandles PDF and audio file operations with URI-based file saving and type detection.
- Infrastructure: Single Linux VM running Nginx + Gunicorn (15 workers, 4 threads per worker, max 60 concurrent requests) + PostgreSQL 15; deployment scripted via shell/rsync.
-
Monitoring: Basic health checks (
/core/health/) + Django request logging; Log tail endpoint (/core/logs/tail) available for debugging. - Logging: Structured logs to stdout (captured by journald); sensitive fields scrubbed manually in log statements.
- Security Controls: HTTPS termination with Nginx, JWT authentication, S3 bucket policies for security.
- Backup & Recovery: DB regular backup, S3 artifact storage with Intelligent-Tiering.
- Compliance: Raw user audio is not stored; only consent metadata and request logs are tracked for auditability in the compliance roadmap.
- Frontend Code Quality: Spotless for Kotlin formatting, ktlint, JaCoCo for coverage verification.
- Backend Code Quality: isort + black + ruff formatting, pre-commit hooks & workflows for automatic checks. pytest-cov for testing.
-
Implemented & in use:
- Authentication (signup, login, logout with JWT)
- Assignment CRUD with S3 presigned URLs for PDF uploads
- Personal assignment answer submission flow with audio file uploads
- Tail-question generation and retrieval
- Class and student management (CRUD operations)
- Teacher dashboard statistics
- Curriculum analysis reports (
/reports/<class_id>/<student_id>/)
-
Integration notes:
- Frontend uses Retrofit with JWT token injection via Interceptor
- Error responses are mapped to user-friendly Korean messages via
ErrorMessageMapper - File uploads use S3 for PDF, multipart data for audio files
- Backend serves presigned S3 url to frontend
- Network timeouts configured: 60s connect, 120s read, 60s write
-
Known limitations:
- Room database for local caching is not currently used
The VoiceTutor system employs a multi-stage AI pipeline to extract meaningful signals from student responses, generating adaptive questions and optimizing curriculum alignment. This section details the question generation workflows, confidence analysis, and achievement standard inference.
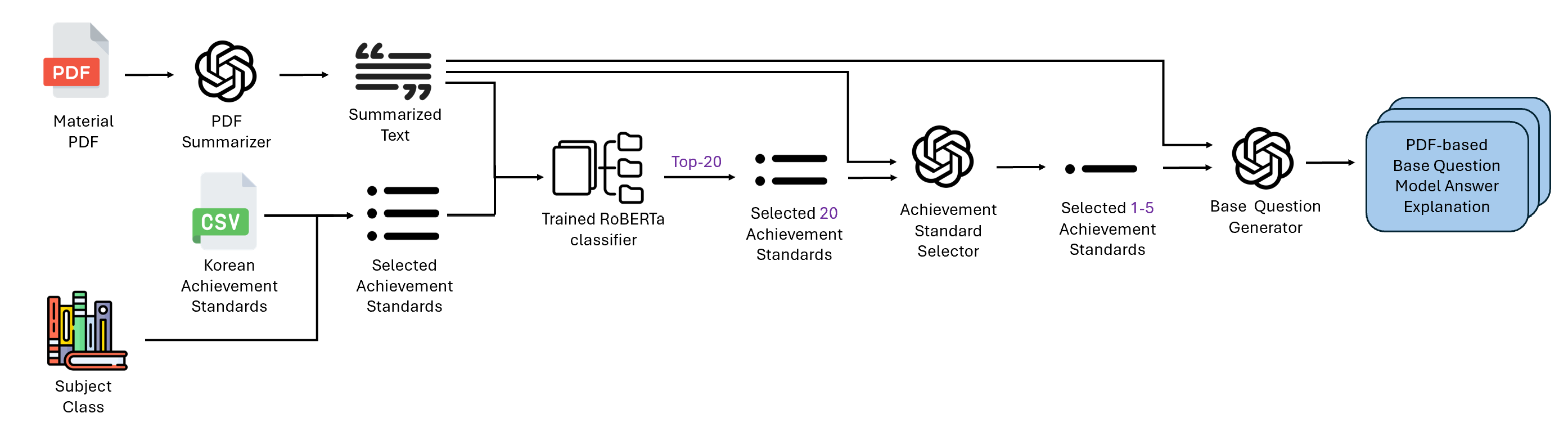
Base questions are generated from PDF learning materials via a multi-stage pipeline orchestrated in backend/questions/views.QuestionCreateView.post:
- PDF summarization: The uploaded PDF is first converted to text via OCR/extraction, then summarized using GPT-4o to produce a concise abstract capturing key concepts.
-
Achievement code inference: The summary is passed to
infer_relevant_achievement_codes_from_summary()(detailed in §4.3), which returns 1-5 curriculum achievement standard codes aligned with the material content. -
Question generation: The summary and inferred achievement codes are provided as context to GPT-4o via a structured prompt template (
multi_quiz_promptinbackend/questions/utils/base_question_generator.py).
Prompt Engineering:
- System role: "Expert educational quiz designer" who creates review questions aligned with learning materials.
- Few-shot examples: Three hand-crafted exemplars demonstrating high-quality questions with clear educational intent (e.g., conceptual reasoning rather than rote recall).
-
Task specification: Generate
ndistinct questions (typically 3-5 per material), each focusing on a different topic within the summary. -
Quality constraints:
- Each question must assess understanding or reasoning, not mere factual recall.
- Avoid generic phrasing (e.g., "Why is X important?").
- Questions should be suitable for elementary/middle school Korean students.
- Difficulty levels (easy/medium/hard) are explicitly labeled.
- No LaTeX notation; math is written in plain text (e.g., "x > 4").
- Achievement alignment: Questions should reflect the goals represented by the inferred achievement codes.
-
Output format: JSON array of objects, each containing
{question, model_answer, explanation, difficulty}.
Model configuration: GPT-4o with temperature=0.5 (moderate creativity) and 90-second timeout. The system retries up to 3 times on API failures or malformed JSON outputs.
Factory instantiation: Generated questions are persisted via BaseQuestionFactory.create_question(), which sets recalled_num=0 and base_question=None to mark them as root nodes in the question chain.
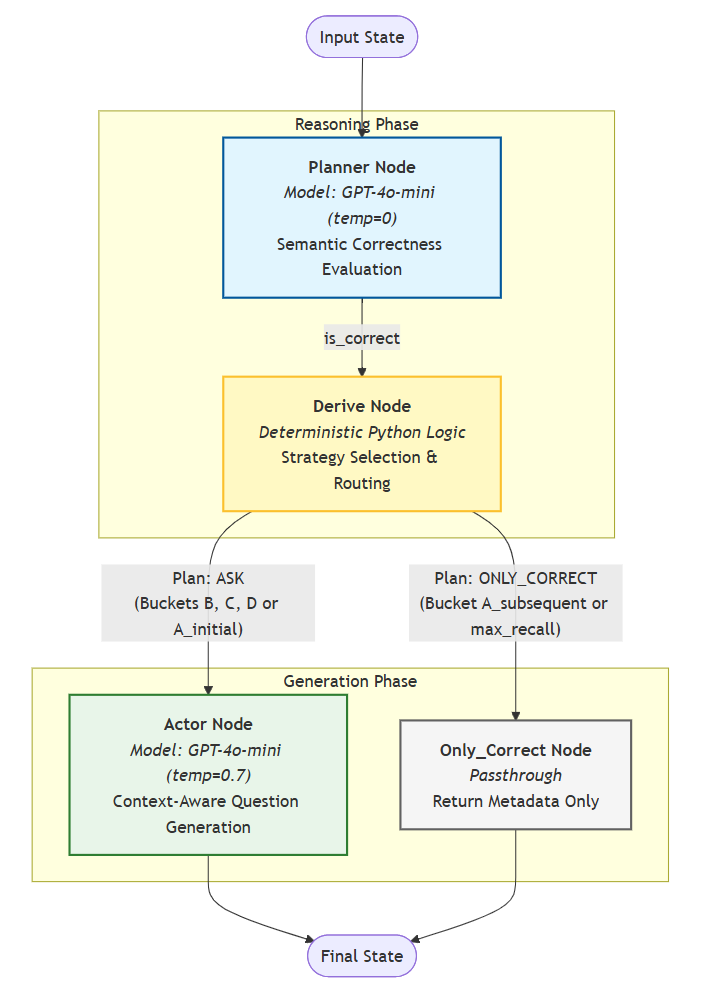
Tail (follow-up) questions are dynamically generated in response to student answers using a LangGraph workflow (backend/submissions/utils/tail_question_generator/generate_questions_routed.py). The workflow implements a planner-actor architecture with rule-based routing to adapt question difficulty and focus based on student performance.
Workflow Architecture:
The LangGraph state machine consists of four nodes:
-
Planner node: A GPT-4o-mini agent (temperature=0, JSON mode) evaluates the student's transcribed answer against the model answer using chain-of-thought reasoning. It outputs:
-
is_correct: Binary correctness judgment. -
reasoning: Step-by-step justification of the assessment.
-
-
Derive & route node: Deterministic Python function that:
- Combines
is_correct(from planner) with the ML-inferred confidence score (eval_grade) to assign the student to one of four buckets via a correctness × confidence matrix:- Bucket A: Correct + High confidence (≥ high_thr) → "ONLY_CORRECT" (no follow-up).
- Bucket B: Correct + Low confidence (< high_thr) → "ASK" (reinforcement question).
- Bucket C: Incorrect + High confidence → "ASK" (misconception correction).
- Bucket D: Incorrect + Low confidence → "ASK" (scaffolding/hint question).
- Selects a strategy and few-shot example tailored to the bucket (e.g., "Ask a slightly harder conceptual extension" for B, "Identify the specific misconception and provide a contrasting example" for C).
- Decides the plan: "ASK" (generate tail question) vs. "ONLY_CORRECT" (skip generation if
recalled_time ≥ 4or bucket A).
- Combines
-
Actor node (conditional on
plan == "ASK"): A GPT-4o-mini agent (temperature=0.7, JSON mode) generates the tail question. The prompt includes:- The original question, model answer, and student answer.
- The selected strategy and few-shot example.
-
Student learning context: A formatted summary of the student's recent performance across the assignment, including:
-
question_chain: Previous attempts on this question number (base + prior tails) with correctness, confidence, and difficulty. -
overall_accuracy: Assignment-wide accuracy rate. -
avg_confidence: Mean confidence score. -
recent_trend: Sequence of recent correctness outcomes (newest first). -
weak_concepts: Optionally provided list of concepts where the student struggles.
-
-
Personalization instructions: The actor is instructed to:
- Avoid repeating questions the student has already answered correctly.
- Address recurring misconceptions with contrasting examples.
- Adjust difficulty based on the student's accuracy trend (increase if improving, simplify if struggling).
- Tailor the question's scaffolding level to the student's confidence patterns.
-
Output format: JSON object with
{topic, question, model_answer, explanation, difficulty}.
-
Only_correct node (conditional on
plan == "ONLY_CORRECT"): Returns a minimal result with no generated question, incrementingrecalled_timeto track progress.
Routing Logic: After the derive node, the graph conditionally routes to either actor (if ASK) or only_correct (if ONLY_CORRECT), then terminates.
Return Value: The final state contains:
-
is_correct,confidence,bucket,plan: Metadata about the student's performance. -
recalled_time: Incremented count of follow-ups on this question chain (capped at 4). -
tail_question: The generated question object (or empty dict if skipped).
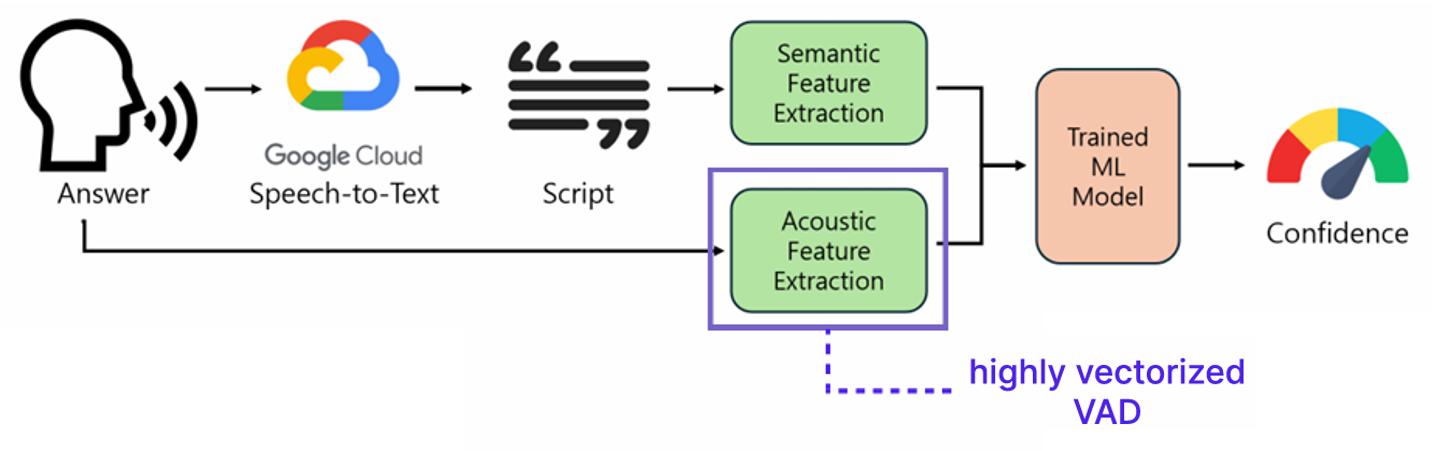
When a student submits a spoken answer via WAV audio file, the system extracts a 25-dimensional feature vector across three complementary modalities: acoustic, linguistic, and semantic. The orchestration is performed by extract_all_features() in backend/submissions/utils/feature_extractor/extract_all_features.py, which sequentially invokes Google Cloud Speech-to-Text API for transcription, followed by feature extractors operating on both the audio signal and the resulting transcript.
Acoustic Features (7 dimensions) are extracted from the raw audio waveform using extract_acoustic_features.py:
-
Prosodic features: Fundamental frequency (f0) statistics computed via PyWorld's DIO + StoneMask algorithm, including
min_f0_hz,max_f0_hz,range_f0_hz, and linear slope measures (tot_slope_f0_st_per_s,end_slope_f0_st_per_s) in semitones per second. These capture pitch variation patterns correlated with speaker confidence and affective state. -
Temporal features: Speech rate (
voc_speedin words/sec) and silence distribution (percent_silence), derived from energy-based voice activity detection with morphological filtering to remove short spurious segments. -
Pause features:
pause_cnt_ratiocomputed as the ratio of detected pauses (silent intervals ≥ 0.5s) to word count.
Linguistic Features (5 dimensions) are extracted from the STT transcript using extract_features_from_script.py:
-
Disfluency markers:
repeat_cnt_ratio(repetition count ratio) andfiller_words_cnt_ratio(frequency of Korean filler words such as "어", "음", "그니까" detected via rule-based lexicon matching with fuzzy tolerance). -
Lexical metrics:
word_speed(words per sentence),avg_sentence_len(average sentence length in words).
Semantic Features (13 dimensions) are computed by encoding the transcript into sentence embeddings using a locally cached Korean SBERT model (snunlp/KR-SBERT-V40K-klueNLI-augSTS, a Sentence-BERT variant fine-tuned on Korean NLI and STS datasets):
-
Adjacent sentence similarity: Distribution statistics (
adj_sim_mean,adj_sim_std,adj_sim_p10,adj_sim_p50,adj_sim_p90) of cosine similarities between consecutive sentence embeddings, capturing local coherence. -
Similarity thresholding:
adj_sim_frac_highandadj_sim_frac_lowmeasure the fraction of adjacent pairs exceeding or falling below predefined similarity thresholds (0.85 and 0.50 respectively), indicating redundancy vs. topic shifts. -
Global coherence:
topic_path_lencomputes the cumulative Euclidean distance along the sentence embedding trajectory, reflecting semantic drift.dist_to_centroid_meananddist_to_centroid_stdmeasure dispersion from the response centroid (mean embedding vector), withcoherence_scoredefined as1.0 - dist_to_centroid_mean. -
Segmented coherence/diversity: The response is divided into three equal temporal segments.
intra_cohaverages within-segment cosine similarities (intra-segment coherence), whileinter_divcomputes1.0 - mean cross-segment similarity(inter-segment diversity).
The pipeline gracefully handles STT failures by substituting a fallback string ("음성 인식 실패") and propagating default feature values (0.0), ensuring robustness to noisy or unintelligible audio inputs.

The extracted 25-dimensional feature vector is fed into a pre-trained XGBoost (v3.0.5) regression model to produce a continuous confidence score. The model, stored as backend/submissions/machine/model.joblib, was trained on an annotated dataset of student speech with human-labeled scoring. Details are described in 4.2.3.
Inference Pipeline (backend/submissions/utils/inference.py):
-
Feature preprocessing: Ratio-based features (
repeat_cnt_ratio,filler_words_cnt_ratio,pause_cnt_ratio) are computed on-the-fly by dividing raw counts byword_cnt. Missing orNonevalues are imputed to 0.0 to prevent null propagation. -
Feature alignment: The 25 features are arranged into a pandas DataFrame with columns ordered according to
FEATURE_COLUMNS(the exact sequence used during training), ensuring input schema consistency. -
Regression prediction: XGBoost predicts a continuous score
pred_cont∈ [1, 8], which is rounded to the nearest integerpred_roundedand clipped to the valid range. -
Grade mapping: The rounded score is mapped to a letter grade via the rule:
A(7-8),B(5-6),C(3-4),D(1-2).
Invalid or failed STT transcripts (detected via marker strings such as "음성 인식 실패" or empty content) trigger an automatic minimum score of 1 (gradeD) -
Output: A dictionary of confidence score (
pred_cont,pred_rounded,pred_letter) is returned for downstream routing decisions.
The model exploits gradient-boosted decision trees to capture nonlinear interactions among acoustic, linguistic, and semantic features, achieving inference latency < 0.4 seconds (excluding feature extraction). The joblib-serialized model is loaded once per server lifetime and cached in memory for efficiency.
The supervised learning pipeline trains an XGBoost gradient boosting regressor to predict numerical grade scores from the 25-dimensional feature vector. The model formulates confidence scoring as a regression problem, mapping feature vectors to a continuous 1–8 scale that is subsequently discretized into letter grades.
Dataset Construction
Training data is collected from annotated presentation recordings stored as JSON label files (*_presentation.json) containing both extracted features and human-assigned grades. The dataset is partitioned into training and validation splits via directory structure (train/ and valid/). Each sample is filtered to exclude recordings with word_cnt = 0 (preventing division-by-zero in ratio computations) and samples with any missing feature values, ensuring data quality. Human evaluators assigned grades on an 8-point scale: { A+: 8, A0: 7, B+: 6, B0: 5, C+: 4, C0: 3, D+: 2, D0: 1 }, which serve as continuous regression targets.
More details about the original dataset can be found in 9.1 Public Speech Dataset.
Model Architecture
We employ XGBoost (XGBRegressor) with histogram-based tree construction (tree_method='hist') for computational efficiency. The regression objective minimizes squared error (reg:squarederror), with RMSE as the evaluation metric. The architecture balances model capacity against overfitting through depth constraints and regularization.
Class Imbalance Handling
Presentation grade distributions are typically skewed toward middle grades (B, C), with fewer samples at extremes (A, D). To prevent the model from biasing toward majority classes, we apply inverse-frequency sample weighting with power-law smoothing:
where
Feature Importance
The trained XGBoost model reveals which features contribute most to confidence score prediction. The top 10 features by gain-based importance are:
Top feature importances:
voc_speed: 0.2167
word_speed: 0.1133
repeat_cnt_ratio: 0.0863
filler_words_cnt_ratio: 0.0630
avg_sentence_len: 0.0351
min_f0_hz: 0.0328
intra_coh: 0.0308
pause_cnt_ratio: 0.0306
adj_sim_frac_low: 0.0287
dist_to_centroid_std: 0.0275
The feature importance ranking reveals that speech fluency is the dominant predictor of confidence. The top four features—voc_speed, word_speed, repeat_cnt_ratio, and filler_words_cnt_ratio—collectively account for approximately 50% of the model's predictive power, all of which measure how smoothly and continuously a student speaks rather than what they say. This suggests that confident students maintain steady speech pacing with minimal repetitions and filler words, while hesitant or uncertain students exhibit slower, fragmented speech patterns with frequent disfluencies.
Linguistic structure features (avg_sentence_len, pause_cnt_ratio) and the acoustic feature min_f0_hz contribute moderately, indicating that sentence completeness, pause frequency, and vocal pitch stability provide additional discriminative signals. The presence of semantic coherence features (intra_coh, adj_sim_frac_low, dist_to_centroid_std) in the top 10 demonstrates that logical organization and topical consistency also matter—students who stay on-topic and maintain coherent reasoning tend to score higher.
Overall, the model effectively captures the intuition that confident responses are characterized by fluent delivery, well-formed sentences, and coherent content structure, while uncertain responses manifest through speech disfluencies, fragmented phrasing, and disjointed topic flow.
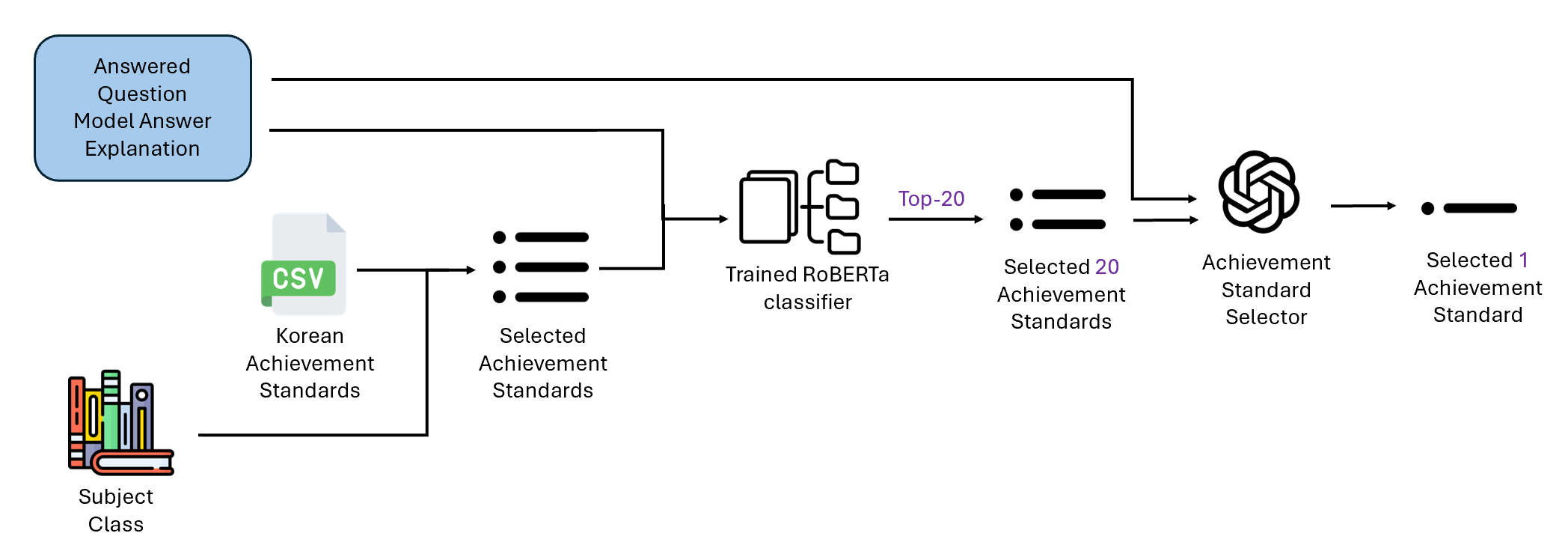
To align generated questions with the Korean 2022 national curriculum standards (1,071 unique achievement codes spanning subjects and grade levels), the system employs a two-stage filtering pipeline that balances accuracy with computational efficiency.
Problem Formulation: Given a PDF summary and metadata (subject, grade), the goal is to identify a small subset (≈20) of achievement codes that best represent the learning objectives. Direct GPT API calls with the full standard list (50-100 codes per subject/school level) would incur prohibitive token costs and latency.
Stage 1: RoBERTa Pre-filtering (backend/reports/utils/achievement_inference.py):
-
Model architecture: A multi-class classifier based on
klue/roberta-large(Korean language understanding model, ~355M parameters) with a custom classification head:- RoBERTa encoder produces contextualized token embeddings.
- CLS token pooling extracts a fixed-size sentence representation.
- Dropout (p=0.1) for regularization.
- Linear classifier projects to 1,071 logits (one per achievement code).
-
Inference process:
- The PDF summary is tokenized (max length 256 tokens).
- The RoBERTa model computes softmax probabilities over all 1,071 codes.
- Only codes corresponding to the current subject/school level (pre-filtered from CSV, typically 50-200 candidates) are retained.
- Top-k=20 codes with highest probabilities are selected.
-
Caching: The model and tokenizer are loaded once and cached in
_model_cache(thread-safe with lock) to amortize loading overhead across requests. - Fallback: If RoBERTa returns <3 results or fails, the system falls back to all subject/school-filtered standards (graceful degradation).
Stage 2: GPT-4o Final Selection (backend/questions/utils/achievement_mapper.py):
- Input: PDF summary + ≤20 RoBERTa-filtered standards (code, content, grade).
-
Prompt engineering:
- System message: "Expert in analyzing curriculum achievement standards."
- User prompt specifies:
- The summary text.
- The filtered standards list (formatted as
Code: <code>\nContent: <content>\nGrade: <grade>). - Selection rules: Return up to
max_codes=5codes that are most directly relevant to the summary. Allow 1-2 codes if only those are clearly relevant. Return empty array[]if none match.
- Output format: JSON array of achievement codes (e.g.,
["2과03-01", "2과03-02"]).
- Model configuration: GPT-4o with temperature=0.1 for consistent, low-variance selection.
- Post-processing: The returned codes are validated against the filtered set (to prevent hallucinated codes) and mapped to their content strings for storage.
Performance Improvements:
- Token reduction: Sending ≤20 standards instead of 50-200 reduces prompt size by 61.3%(average), directly cutting API costs.
- Latency reduction: Smaller context windows enable faster GPT inference (22% faster per question).
- Accuracy preservation: RoBERTa's high recall (trained on curriculum text) ensures relevant codes remain in the top-20, while GPT's reasoning refines precision.
Integration: Achievement codes are inferred in QuestionCreateView.post before calling generate_base_quizzes(), and the codes are passed as context to the question generation prompt. The final codes are stored in the Question.achievement_code field for reporting and analytics (enabling teachers to track student performance by curriculum standard).
To infer Korean national curriculum achievement standards from input text (e.g., PDF summaries), we fine-tuned a supervised multiclass classifier based on klue/roberta-large, a Korean-language transformer model. The training dataset was built from AI Hub - Curriculum-Level Subject Dataset.
Dataset Construction
The training dataset was built from a labeled corpus where each input is either sentence or paragraph-level text aligned with a single achievement standard code (e.g., 9과12-04). Each code is associated with a natural language description (content) derived from the official 2022 Ministry of Education achievement standard document.
- Input: Summary-level educational text (from teacher materials, textbook paragraphs, etc.)
- Label: Single achievement standard code (1,071 unique labels across subjects and grade levels)
Total 1071 achievement standards each paired with 80 sample texts are used for training.
More details about the dataset can be found in Section 9.2: Curriculum-Level Subject Dataset.
Model Architecture & Training Pipeline
-
Base Model:
klue/roberta-large(355M parameters) -
Classification Head: Linear projection over the
[CLS]token for 1,071 classes (softmax output) - Input Length: Truncated or padded to 256 tokens
- Loss Function: Cross-entropy loss (standard for multiclass classification)
- Optimizer: AdamW
- Training Epochs: 5
- Learning Rate: 2e-5 with linear warm-up (10%) and decay
- Batch Size: 32 (gradient accumulation used if GPU memory limited)
- Early Stopping: Based on validation loss (patience = 2 epochs)
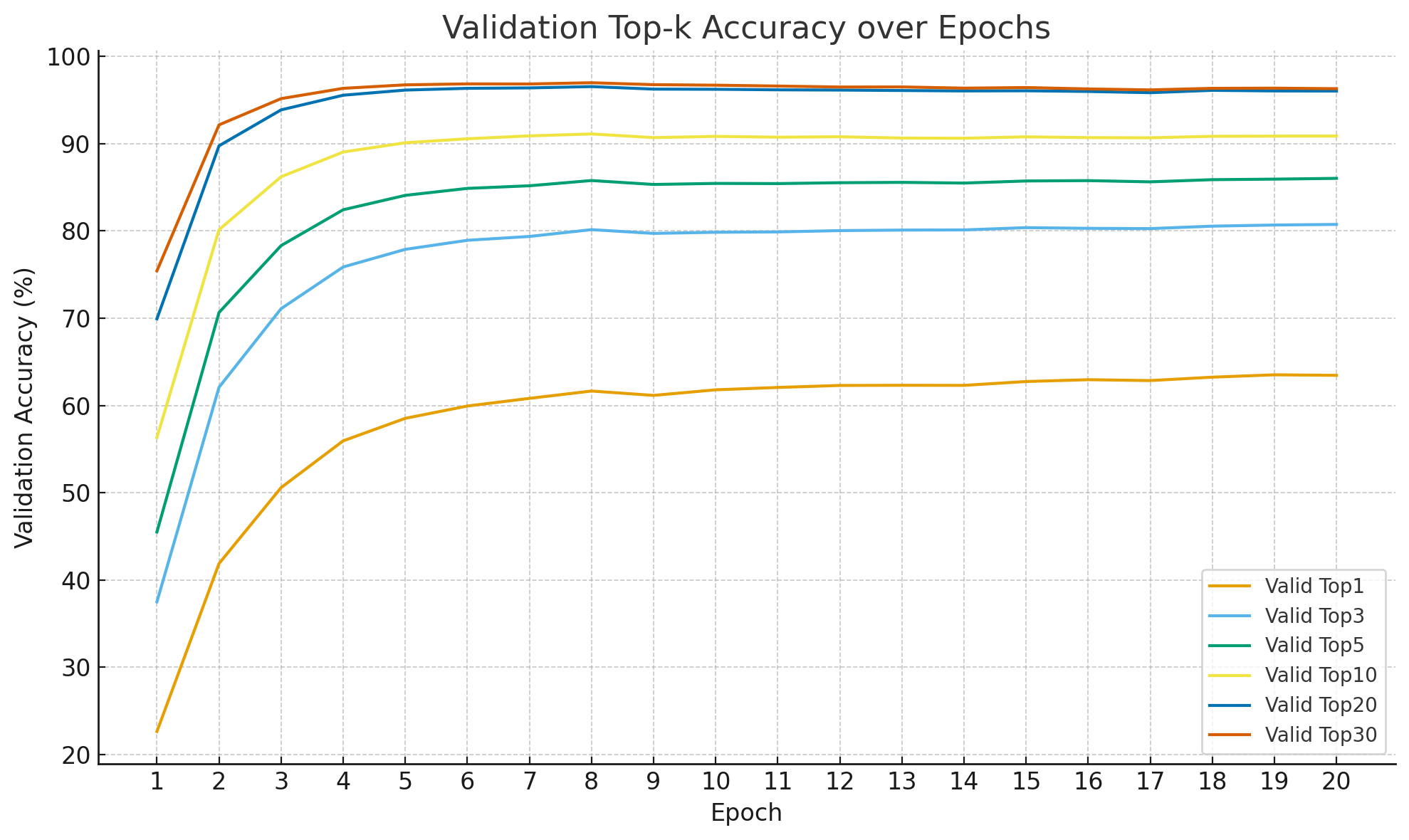
- Evaluation Metric: Top-k accuracy (k = 1, 5, 10, 20)
Training was performed using PyTorch and HuggingFace Transformers. The final model was serialized with torch.save() and exported alongside its tokenizer and code mappings.
Overall, the top-20 accuracy reached approximately 96–97%. Most of the remaining misclassifications were on cases that are also difficult for humans to label accurately, like below.
Upon manual inspection, we found that even when the model's prediction differed from the ground truth, it often produced a reasonable and semantically valid result.
Input Text: 한글 맞춤법은 '표준어를 소리대로 적되, 어법에 맞도록 함'을 원칙으로 삼습니다.
True Code: [9국04-06] 한글 맞춤법의 기본 원리와 내용을 이해하고 국어생활에 적용한다.
Pred Code: [10국04-04] 한글 맞춤법의 기본 원리와 내용을 이해한다.

Inference Procedure
During inference, input text is tokenized and passed to the trained classifier to produce softmax probabilities over all 1,071 classes. The top-k predictions are selected and filtered to ensure consistency with codes present in the training set. Each predicted code is mapped back to its curriculum description using a lookup dictionary constructed from the CSV.
- We use pre-commit to automatically enforce code quality before each commit.
Schedule & Frequency
-
When:
- Conducted continuously during feature development.
- Each developer must run unit tests before creating a PR to develop branch.
- Integration tests are executed every weekend.
-
Frequency:
- Unit Tests → Daily (local development)
- Integration Tests → Weekly (managed by PM)
Responsibilities
-
Developers:
- Write and maintain unit tests for their assigned modules.
- Ensure tests pass before opening PRs.
-
PM:
- Reviews PRs and enforces testing compliance.
- Executes weekly integration tests.
- Frameworks: Pytest
- Architecture: MTV, but templates are not used on backend (API-only).
- Coverage goal: > 90% coverage per component.
-
Testing Result
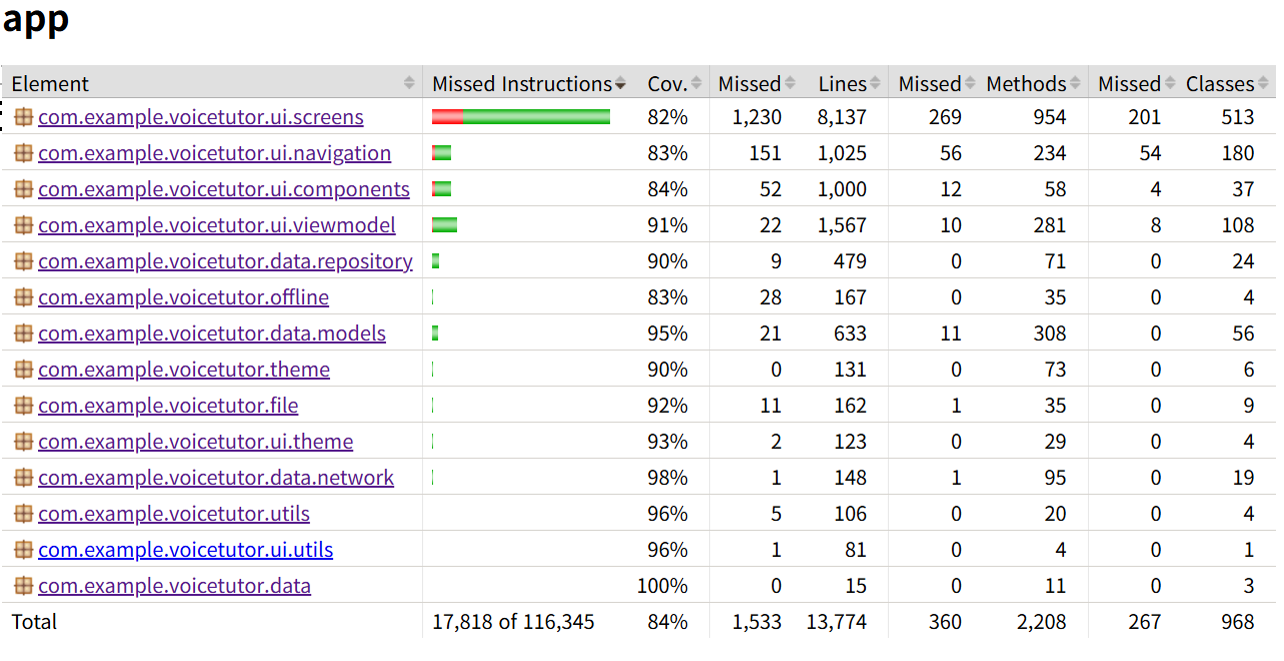
- Passed 532 tests and achieved 93% total coverage.
- Per component coverage: Models: 100%, Views: 97.7%
- Excluded manage.py, migrations, commands for dummy db, test files in tests.
---------- coverage: platform win32, python 3.13.5-final-0 -----------
Name Stmts Miss Cover
--------------------------------------------------------------------------------------------
accounts\admin.py 12 0 100%
accounts\apps.py 4 0 100%
accounts\models.py 32 0 100%
accounts\request_serializers.py 13 0 100%
accounts\serializers.py 31 0 100%
accounts\urls.py 3 0 100%
accounts\views.py 102 23 77%
assignments\admin.py 4 0 100%
assignments\apps.py 4 0 100%
assignments\models.py 31 0 100%
assignments\request_serializers.py 17 0 100%
assignments\serializers.py 31 0 100%
assignments\urls.py 3 0 100%
assignments\views.py 200 0 100%
catalog\admin.py 3 0 100%
catalog\apps.py 4 0 100%
catalog\models.py 6 0 100%
catalog\request_serializers.py 3 0 100%
catalog\serializers.py 6 0 100%
catalog\urls.py 4 0 100%
catalog\views.py 15 0 100%
core\admin.py 0 0 100%
core\apps.py 4 0 100%
core\authentication.py 26 4 85%
core\models.py 0 0 100%
core\urls.py 4 0 100%
core\views.py 13 0 100%
courses\admin.py 4 0 100%
courses\apps.py 4 0 100%
courses\models.py 25 0 100%
courses\request_serializers.py 20 0 100%
courses\serializers.py 64 0 100%
courses\urls.py 3 0 100%
courses\views.py 285 11 96%
questions\admin.py 3 0 100%
questions\apps.py 4 0 100%
questions\factories.py 25 5 80%
questions\models.py 23 0 100%
questions\request_serializers.py 11 0 100%
questions\serializers.py 23 0 100%
questions\urls.py 3 0 100%
questions\utils\achievement_mapper.py 107 0 100%
questions\utils\base_question_generator.py 79 8 90%
questions\utils\pdf_to_text.py 35 1 97%
questions\views.py 125 3 98%
reports\admin.py 0 0 100%
reports\apps.py 4 0 100%
reports\models.py 0 0 100%
reports\serializers.py 17 0 100%
reports\urls.py 4 0 100%
reports\utils\achievement_inference.py 160 15 91%
reports\utils\analyze_achievement.py 199 23 88%
reports\views.py 31 0 100%
submissions\admin.py 4 0 100%
submissions\apps.py 4 0 100%
submissions\models.py 37 0 100%
submissions\serializers.py 37 0 100%
submissions\urls.py 3 0 100%
submissions\utils\feature_extractor\extract_acoustic_features.py 189 22 88%
submissions\utils\feature_extractor\extract_all_features.py 36 2 94%
submissions\utils\feature_extractor\extract_features_from_script.py 285 67 76%
submissions\utils\feature_extractor\extract_semantic_features.py 76 0 100%
submissions\utils\inference.py 36 3 92%
submissions\utils\tail_question_generator\generate_questions_routed.py 153 1 99%
submissions\utils\wave_to_text.py 41 4 90%
submissions\views.py 414 40 90%
voicetutor\settings.py 48 0 100%
voicetutor\urls.py 7 0 100%
--------------------------------------------------------------------------------------------
TOTAL 3203 232 93%
======================== 532 passed, 416 warnings in 217.01s (0:03:37) ========================
-
Backend Integration Test Summary
- Verified end-to-end workflows for both teacher and student flows.
- Checked error handling for invalid requests, missing parameters, and unknown resources.
- Ensured proper linking across modules (auto personal assignment creation, enrollment relations).
- Confirmed cascade delete rules function correctly.
The backend uses pytest as the primary testing framework with the following key components:
- pytest (v8.3.4): Main testing framework
- pytest-django (v4.9.0): Django integration for pytest
- pytest-cov (v6.0.0): Code coverage reporting
- pytest-mock (v3.15.1): Mocking utilities
- factory_boy (v3.3.1): Test data generation
- coverage (v7.11.0): Coverage analysis tool
Tests are organized within each Django app under a tests/ directory:
accounts/tests/assignments/tests/catalog/tests/core/tests/courses/tests/questions/tests/reports/tests/submissions/tests/-
tests/(integration tests)
Unit Tests
- Model Tests: Test model validation, relationships, and business logic
- Serializer Tests: Test request/response serialization and validation
- View Tests: Test API endpoints, authentication, authorization, and response formats
- Utility Tests: Test helper functions and utility modules
Integration Tests
- Located in
backend/tests/test_integration.py - Test complete workflows (e.g., teacher workflow: signup → class creation → student enrollment → assignment creation)
- Use Django's
APIClientfor end-to-end API testing
Fixtures Tests use pytest fixtures for reusable test data setup:
@pytest.fixture
def api_client():
return APIClient()
@pytest.fixture
def teacher():
return Account.objects.create_user(...)
@pytest.fixture
def course_class(teacher, subject):
return CourseClass.objects.create(...)Database Access
All tests use pytestmark = pytest.mark.django_db to enable database access. Tests use an in-memory SQLite database by default (configured via Django settings).
Mocking
- Use
unittest.mock.patchfor mocking external services (e.g., AWS S3, Google Cloud Speech) - Mock external API calls and file operations
- Use
factory_boyfor generating test data
Test Markers Pytest markers are used to categorize tests:
-
@pytest.mark.slow: Marks slow-running tests (can be deselected with-m "not slow") -
@pytest.mark.integration: Marks integration tests
Test configuration is defined in backend/pytest.ini:
- Django settings module:
voicetutor.settings - Test file patterns:
tests.py,test_*.py,*_tests.py - Test paths: All app directories containing tests
- Default options: Short traceback format, strict markers, disabled warnings
# Run all tests
pytest
# Run tests for a specific app
pytest assignments/tests/
# Run specific test file
pytest assignments/tests/test_assignment_apis.py -v
# Run with coverage
pytest --cov=. --cov-report=html
# Skip slow tests
pytest -m "not slow"-
Frameworks: JUnit 4, Mockito (5.11.0), Mockito-Kotlin (5.4.0), Turbine (1.0.0), Compose UI Test, Hilt Testing
-
Architecture: MVVM (ViewModel + Repository pattern)
-
Coverage goal: > 80% coverage per component.
-
Coverage enforcement: JaCoCo with
jacocoTestCoverageVerificationtask -
Testing Result
-
Test Organization:
- Unit tests: 1200+ tests covering ViewModels, Repositories, Utils, Managers
- Instrumentation tests: Split into 5 groups (connectedDebug1-5), total 900+ tests
- Total test count: 2100+ tests across unit and instrumentation suites
-
Frontend Integration Test Summary
- Screen workflows: ui, button, text and functionality checks for every screens
- Authentication workflows: signup, login, token management
- Assignment lifecycle: create, edit, delete, submit with file uploads
- Navigation flows: student/teacher dashboard navigation, deep linking
- UI state transitions: loading, error, success states with proper error messages
- Form validation: text input validation, date/time picker interactions
- File operations: PDF upload, audio recording simulation

The Android frontend uses a comprehensive multi-layered testing approach with both unit tests and instrumentation tests:
- JUnit 4: Core testing framework
- Mockito (v5.11.0) & Mockito-Kotlin (v5.4.0): Mocking framework
- Turbine (v1.0.0): Flow testing library for Kotlin Coroutines
- kotlinx-coroutines-test (v1.8.1): Coroutine testing utilities
- AndroidX Test: Android testing framework
- Espresso: UI interaction testing
- Compose UI Test: Jetpack Compose UI testing
- Hilt Testing: Dependency injection testing support
- MockK (v1.13.10): Mocking library for Kotlin (used in some instrumentation tests)
Unit Tests (src/test/java/com/example/voicetutor/)
-
ViewModels:
ui/viewmodel/*Test.kt- Test ViewModel logic, state management, and business logic (AuthViewModel, AssignmentViewModel, ClassViewModel, StudentViewModel, etc.) -
Repositories:
data/repository/*Test.kt- Test data layer, API interactions, error handling -
Models:
data/models/*Test.kt- Test data model validation and transformations -
Network:
data/network/*Test.kt- Test API configuration and network models -
Utils:
utils/*Test.kt- Test utility functions (DateFormatter, StatisticsCalculator, PermissionUtils, ErrorMessageMapper) - Managers: Test OfflineManager, ThemeManager, FileManager functionality
Instrumentation Tests (src/androidTest/java/com/example/voicetutor/)
-
Screen Tests:
ui/screens/*Test.kt- End-to-end UI tests for complete screens (CreateAssignmentScreen, EditAssignmentScreen, AssignmentDetailedResultsScreen, etc.) -
Coverage Tests:
ui/screens/*CoverageTest.kt- High-coverage tests targeting specific line ranges and edge cases -
Navigation Tests:
ui/navigation/*Test.kt- Navigation flow tests (VoiceTutorNavigation, MainLayout navigation) -
Component Tests:
ui/components/*Test.kt- UI component tests (Button, TextField, Card, Header, etc.) -
Hilt-based Tests: All instrumentation tests use
@HiltAndroidTestwithFakeApiServicefor deterministic API responses
ViewModel Testing
@RunWith(MockitoJUnitRunner::class)
class AuthViewModelTest {
@get:Rule
val mainDispatcherRule = MainDispatcherRule()
@Mock
lateinit var authRepository: AuthRepository
@Test
fun signup_success_setsAutoFillAndCurrentUser() = runTest {
// Given
val vm = AuthViewModel(authRepository)
Mockito.`when`(authRepository.signup(...))
.thenReturn(Result.success(user))
// When
vm.signup(...)
advanceUntilIdle()
// Then
vm.currentUser.test { ... }
}
}Flow Testing with Turbine
vm.currentUser.test {
val user = awaitItem()
assert(user != null)
cancelAndIgnoreRemainingEvents()
}Repository Testing
- Mock
ApiServiceusing Mockito - Test success and failure scenarios
- Verify error handling and exception propagation
- Test network response parsing with Gson
Compose UI Testing (Instrumentation)
- Use
createAndroidComposeRule<MainActivity>()for Compose UI tests - Test UI semantics with
onNodeWithText,onNodeWithContentDescription,performClick, etc. - Use
waitUntilandwaitForIdlefor asynchronous UI updates - Test Material3 components (ModalBottomSheet, DatePickerDialog, TimePickerDialog)
Instrumentation Testing with Hilt
@HiltAndroidTest
@RunWith(AndroidJUnit4::class)
class CreateAssignmentScreenHighCoverageTest {
@get:Rule(order = 0)
val hiltRule = HiltAndroidRule(this)
@get:Rule(order = 1)
val composeRule = createAndroidComposeRule<MainActivity>()
@Inject
lateinit var fakeApi: FakeApiService
@Test
fun testFileUploadSuccessAndFileListUI() {
// Test implementation using FakeApiService
// No need to mock ViewModels - Hilt provides real instances with fake API
}
}Test configuration is defined in frontend/app/build.gradle.kts:
Test Options
-
isIncludeAndroidResources = true: Include Android resources in unit tests -
isReturnDefaultValues = true: Return default values for Android framework calls -
animationsDisabled = true: Disable animations during tests - Custom test runner:
HiltTestRunnerfor instrumentation tests - Split test execution: Tests organized into 5 groups (connectedDebug1-5) for optimized CI/CD performance
Code Coverage (JaCoCo)
- JaCoCo (v0.8.11): Code coverage tool
- Coverage reports generated for both unit tests and Android tests
- Minimum coverage requirement: 80% overall, 70% per class
- Coverage reports available in HTML and XML formats
- Custom exclusions: Hilt-generated classes, R files, BuildConfig
Unit Tests
# Run all unit tests
./gradlew testDebugUnitTest
# Run specific test class
./gradlew testDebugUnitTest --tests "AuthViewModelTest"
# Generate coverage report
./gradlew jacocoTestReportInstrumentation Tests
# Run all Android instrumentation tests (requires connected device/emulator)
./gradlew connectedDebugAndroidTest
# Alternative
# Run specific test groups (faster execution, make sure not to override coverage.ec file)
# You should manually copy and store coverage.ec files not to lose previous test results!
./gradlew connectedDebug1 # UI components and basic navigation
./gradlew connectedDebug2 # Screen tests
./gradlew connectedDebug3 # Additional screen tests
./gradlew connectedDebug4 # Complex screen workflows
./gradlew connectedDebug5 # High-coverage tests and navigation
# Generate combined coverage report
./gradlew jacocoTestReportCoverage Verification
# Verify coverage meets minimum requirements (80%)
./gradlew jacocoTestCoverageVerificationUnit Tests Cover:
- ViewModel state management and business logic
- Repository data access and error handling
- Data model validation and transformations
- Utility functions (date formatting, statistics, permissions)
- Manager classes (OfflineManager, ThemeManager, FileManager)
- Network error mapping and API response handling
Instrumentation Tests Cover:
- Complete screen workflows (CreateAssignment, EditAssignment, AssignmentDetail, etc.)
- UI component interactions (buttons, text fields, dialogs, date/time pickers)
- Navigation flows (VoiceTutorNavigation, MainLayout)
- Compose UI semantics and accessibility
- Real device/emulator behavior with Hilt dependency injection
- Isolation: Each test is independent and can run in any order
- Mocking: External dependencies are mocked to ensure fast, reliable tests (Mockito for unit tests, FakeApiService for instrumentation tests)
-
Coroutine Testing: Use
runTestandadvanceUntilIdle()for testing coroutines - Flow Testing: Use Turbine for testing Kotlin Flows
- Test Data: Use FakeApiService with predefined responses for consistent instrumentation tests
- Coverage: Maintain high test coverage (target: 80% for frontend, 90% for backend)
- CI/CD: Tests split into 5 groups for parallel execution and faster CI/CD pipelines
- Pre-commit: Spotless enforces Kotlin code formatting before each commit
-
Hilt Testing: Use
@HiltAndroidTestwith customHiltTestRunnerfor dependency injection in instrumentation tests
Both frontend and backend tests are integrated into development workflows:
- Pre-commit hooks: Spotless formatting checks run automatically before commits
- Local testing: Developers run unit tests before creating PRs
- Coverage verification: JaCoCo enforces > 80% coverage
- Test groups: Android instrumentation tests split into 5 groups (connectedDebug1-5) for optimized execution
- CI/CD readiness: GitHub Actions configuration for automated format checks and automated deployment
Selected User Stories
- Teacher creates a new class and enrolls a new student
- As a registered teacher user,
- I can create a new class with a title, subject, and description, and enroll students into the class,
- so that I can organize enrolled students and assignments separately by class.
- Teacher generates a quiz from a pdf material
- As a registered teacher user who manages a class,
- I can upload a PDF learning material and generate a quiz assignment from it,
- so that enrolled students can view and take the quiz.
- Student participates in a voice quiz session
- As a registered student user enrolled in the class,
- I can start a conversational quiz session and submit my spoken answers,
- so that my submission is recorded and I can receive AI-generated follow-up questions tailored to my weak areas.
- Student reviews their assignment
- As a registered student user enrolled in the class,
- I can review my completed assignment and view the report.
- so that I can understand which questions I answered correctly or incorrectly.
- Teacher accesses student's statistics and reports
- As a registered teacher user who manages the class,
- I can access each enrolled student's statistics and reports based on Korean curriculum standards,
- so that I can assess their understandings and identify weak areas
Responsibilities
-
PM:
- Plan and coordinate acceptance testing sessions.
- Verify that each selected user story meets acceptance criteria.
-
Developers:
- Support setup, fix identified bugs, and assist in validation.
Schedule
- Conducted at 12/4.
Result
- passed all 69 test cases
Feedbacks
-
The Student Registration and Delete buttons being visible only after scrolling is inconvenient.
→ Updated so the buttons are now fixed at the bottom. -
When skipping a question, showing “Grading…” feels awkward; it would be better to indicate that a new question is being generated.
→ Changed the message to “Grading & Generating Question”. -
When expanding a tail question, it’s hard to notice that it actually opened.
→ Adjusted the behavior so clicking “Expand Tail Question” automatically scrolls down slightly to reveal the generated tail question.
Frontend:
- UI Framework: Jetpack Compose (Material3, Navigation Compose, Lifecycle ViewModel Compose)
- Networking: Retrofit 2 with Gson converter, OkHttp with logging interceptor
- Dependency Injection: Hilt (Dagger-based DI for Android)
- Image Loading: Coil Compose
- Testing: JUnit 4, Mockito (5.11.0), Mockito-Kotlin (5.4.0), Turbine (1.0.0), Compose UI Test, Hilt Testing
- Code Quality: Spotless (Kotlin formatting), JaCoCo (0.8.11) for code coverage
Backend:
- Framework: Django REST Framework
- Database: PostgreSQL 15 with psycopg3
- AI/ML: LangChain, LangGraph, OpenAI GPT-4o/GPT-4o-mini, Google Cloud Speech-to-Text API
- ML Models: XGBoost for confidence scoring
- Testing: Pytest (8.3.4), pytest-django, pytest-cov, pytest-mock, factory_boy, coverage (7.11.0)
Storage & Infrastructure:
- Cloud Storage: AWS S3 for material PDFs
- Web Server: Nginx + Gunicorn (15 workers, 4 threads per worker)
Implemented Risk Mitigation Strategies:
| Risk | Impact | Likelihood | Mitigation Strategy (Implemented) | Implementation Location |
|---|---|---|---|---|
| Database transaction failures | High | Medium | Django transaction.atomic() ensures atomic operations with automatic rollback on exceptions for question generation operations |
backend/questions/views.py (line 141) |
| Network timeout during API calls | High | High | OkHttpClient timeout configuration (60s connect, 120s read, 60s write), user-friendly error messages |
frontend/app/src/main/java/com/example/voicetutor/di/NetworkModule.kt (lines 45-47) |
| Partial data saves on creation failures | High | Medium | Try-except blocks catch exceptions before database commits; errors return user-friendly Korean messages | All backend views (e.g., backend/assignments/views.py, backend/courses/views.py) wrap operations in try-except |
| API error response inconsistency | Medium | Medium | Standardized create_api_response() helper function returns consistent error format with Korean messages |
backend/assignments/views.py (line 27), backend/courses/views.py (line 31), backend/submissions/views.py (line 32) |
| Exception message exposure to users | Low | Medium | Backend catches exceptions and returns user-friendly Korean messages (e.g., "과제 목록 조회 중 오류가 발생했습니다"); frontend displays server-supplied messages | All backend views wrap operations in try-except blocks |
Planned Risk Mitigation Strategies:
| Risk | Impact | Likelihood | Mitigation Strategy (Planned) |
|---|---|---|---|
| Offline submission backlog | Medium | High |
OfflineManager class implemented with file-based caching and pending action queue (max 3 retries); integration with ViewModels and production workflows pending |
| AI scoring drift produces biased feedback | High | Medium | Golden-set evaluation, regular human review |
| STT outage or degraded accuracy | High | Medium | Multi-region STT endpoints, fallback provider (Google Cloud Service), pre-cached prompts for manual transcription |
| PDF parsing failure on complex documents | Medium | Medium | Graceful fallback to manual question creation, PDF preprocessing heuristics, validation before publish |
| Data breach of stored audio files | Critical | Low | Signed URL expiry (5 min), access logging, strict s3 policy for security |
- Tail Question: Follow-up AI question triggered when accuracy/confidence below threshold.
- Certainty / Confidence Score: Probability (0-1) returned by evaluation model representing confidence in correctness classification.
-
Achievement Code: Identifier aligned with Korean national curriculum competency mapping (e.g.,
9과12-04). - Guardian Consent: Verified authorization from legal guardian for minors, stored with versioned policy reference.
- Golden Set: Curated dataset of labeled student responses used to evaluate AI performance.
- Korean Ministry of Education Curriculum Standards (2022 revision)
- OWASP ASVS v4.0.3
- WCAG 2.1 AA Guidelines
- ISO/IEC 27001 Control Mapping for Education Technology
Link: AI Hub — Public Speaking Practice & Assessment Data
This dataset was constructed to support public speaking practice and assessment.
It contains presentation videos and speech audio, presentation text materials, and evaluation text data.
The goal is to enable research and development in:
- Public speaking recognition and classification
- Speaking level evaluation
| Code | Group | Count | Ratio |
|---|---|---|---|
| A00 | Middle school (Grade 9) | 100 | 12.5% |
| A01 | High school students | 200 | 25% |
| A02 | 20s | 200 | 25% |
| A03 | 30s | 100 | 12.5% |
| A04 | 40s | 100 | 12.5% |
| A05 | 50+ | 100 | 12.5% |
- Length: 3~4 min per presentation
- Speakers: Metadata includes age group, gender, occupation, and audience type.
- Presentations: Topic, type, location, script text, and difficulty level.
- Utterances: Speech segments with start/end time, syllable count, word count, sentence count, and STT-based transcription.
- Metadata: File ID, filename, evaluation date, and data format.
| Category | Field | Description | Type |
|---|---|---|---|
| Speaker Info | speaker |
Speaker ID | String |
age_flag |
Age group | String | |
gender |
Gender | String | |
job |
Occupation | String | |
aud_flag |
Audience group | String | |
| Presentation Info | presentation |
Presentation ID | String |
presen_topic |
Presentation topic | String | |
presen_type |
Presentation type | String | |
presen_location |
Presentation location | String | |
presen_script |
Original presentation script | String | |
presen_difficulty |
Presentation difficulty | String | |
| Utterance Script | script |
Utterance ID | String |
start_time |
Utterance start time | String | |
end_time |
Utterance end time | String | |
script_stt_txt |
Utterance content (ASR/STT result) | String | |
script_tag_txt |
Utterance content (tag-mapped) | String | |
syllable_cnt |
Number of syllables | Number | |
word_cnt |
Number of words (tokens) | Number | |
audible_word_cnt |
Number of words clearly perceived by listener | Number | |
sent_cnt |
Number of sentences | Number | |
| Evaluation | evaluations |
Evaluation entry ID | String |
evaluation.eval_id |
Evaluator ID | String | |
eval_flag |
Evaluator type | String | |
eval_grade |
Overall evaluation grade | String | |
| Repetition | repeat_cnt |
Count of repetitions/self-repairs | Number |
repeat_scr |
Repetition/self-repair score | Number | |
| Filler Words | filler_words_cnt |
Count of fillers (um, uh, etc.) | Number |
filler_words_scr |
Filler word score | Number | |
| Pause | pause_cnt |
Count of pauses | Number |
pause_scr |
Pause score | Number | |
| Pronunciation | wrong_cnt |
Count of pronunciation errors | Number |
wrong_scr |
Pronunciation score | Number | |
| Voice Quality | voc_quality |
Voice quality label | String |
voc_quality_scr |
Voice quality score | Number | |
| Voice Speed | voc_speed |
Speech rate (words/sec) | Float |
voc_speed_sec_scr |
Speech rate score | Number | |
| Tagging | taglist |
Tag list | String |
tag_id |
Tag ID | String | |
tag_keyword |
Tag keyword | String | |
tag_type |
Tag type | Integer | |
| Averages | repeat_scr |
Average repetition/self-repair score | Float |
filler_words_scr |
Average filler word score | Float | |
pause_scr |
Average pause score | Float | |
wrong_scr |
Average pronunciation score | Float | |
voc_quality_scr |
Average voice quality score | Float | |
voc_speed_sec_scr |
Average speech rate score | Float | |
eval_grade |
Average overall evaluation grade | String | |
| Meta | info.filename |
File name | String |
id |
File ID | String | |
date |
Evaluation date | String | |
formats |
Data format | String |
| Organization | Responsibility |
|---|---|
| HealthCloud Co., Ltd. | Non-verbal data refinement & processing |
| GNUSoft Co., Ltd. | Linguistic AI modeling |
| ANeut Co., Ltd. | Non-verbal processing, AI modeling, authoring tools |
-
Overview This dataset is designed to support research in curriculum-aligned natural language understanding and multimodal learning. It was constructed through the systematic collection of textual and visual data from official educational materials, such as textbooks and reference guides, across multiple educational stages. These resources were then rigorously annotated and aligned with the achievement standards defined in the 2022 Revised National Curriculum of Korea, across nine core subject domains. The resulting dataset facilitates a range of educational AI tasks, including curriculum-based content inference, standard-level classification, and subject-specific knowledge modeling.
-
Subjects: Science, Korean, Mathematics, English, Social Studies, Sociology, Ethics, Technology–Home Economics, Information (9 subjects in total)
-
Preprocess: The dataset is partitioned into training and validation sets, each containing 80 textual samples per achievement standard to ensure balanced representation across labels.
-
Distribution:
After preprocessing, we collected a total of 1,071 achievement standards, each paired with 80 sample texts—resulting in 85,680 samples overall.Subject Number of Standards Total Samples Science 190 15,200 Korean 209 16,720 Technology and Home Economics 86 6,880 Ethics 21 1,680 Social Studies 173 13,840 Society and Culture 13 1,040 Math 241 19,280 English 84 6,720 Informatics 54 4,320 Total 1071 85,680 -
Contributors: Media Group Sarangwasup Co., Ltd.
Recognizing Uncertainty in Speech
- Published: 2011 (57 citations)
The study investigates how prosody (intonation, stress, and speech rate) differs when a speaker is confident versus uncertain, and whether these cues appear across the whole utterance or are localized around critical/target words.
-
Participants / utterances
- 20 speakers: all native English
- 5 raters
- 600 utterances total
-
Scripts
- Boston public transportation fill-in-the-blank sentences
- Lexical fill-in-the-blank sentences (with unfamiliar words inserted)
-
Procedure
- Speakers recorded their self-rated confidence (1–5)
- Raters judged perceived confidence (1–5)
-
Features Used
-
Pitch (f0)
- minimum, maximum, mean, std, range
- relative position in utterance of min pitch
- relative position in utterance of max pitch
- absolute slope
-
Intensity (RMS)
- minimum, maximum, mean, std
- relative position in utterance of min intensity
- relative position in utterance of max intensity
-
Temporal
- total silence, percent silence
- total duration
- speaking duration (utterance length − pauses)
- speaking rate
-
-
Normalization
-
z-score normalization per speaker
- For each speaker, all utterances were used to compute ((x - \mu)/\sigma)
- Each speaker’s mean centered to 0 and std to 1
- This cancels baseline pitch/loudness/speaking style differences
-
-
Total duration (−0.653)- Sentence length was nearly fixed in this setup; not relevant for our service
-
Total silence (−0.644)
-
Speaking duration (−0.515)- Same issue as above; discarded
-
Percent silence (−0.459)
-
Absolute slope of f0 (+0.312)
- Larger values correspond to final rising intonation (questions) or sharp final falls (statements)
- Likely: final falls (r < 0) = confidence
- Suggestion: compute f0 slope specifically at the end of the utterance as a feature
-
f0 range
- Larger range = more variation in pitch → likely uncertainty
-
min f0, max f0
- Very low minima or very high maxima = uncertainty (similar effect as large range)
-
min RMS
- Very low intensity suggests uncertainty (quiet speech perceived as low confidence)
- Mismatch: sometimes speakers reported low confidence, but raters perceived them as confident
- Indicates that apparent confidence ≠ actual confidence; speakers may project certainty despite inner doubt
- How to adapt speaker-wise normalization when user data is sparse remains an open question
- No explicit model/weights were suggested for combining features into an ML predictor of uncertainty
- Study limited to English speakers; Korean prosody may differ
- Sentence length was artificially fixed, so features tied to total duration are unsuitable for deployment
-
Correct + Uncertain: “You identified the right idea. Let’s review it once more to solidify your reasoning.”
-
Incorrect + Confident: “This is a common misconception. Let’s carefully compare the key differences.”
Response latency as a predictor of the accuracy of children's reports
- published in 2011 (69 citations)
As obvious as it may sound,
the longer a student takes to select an answer, the more uncertain they are.
Although the study was conducted in a multiple-choice selection scenario (not directly aligned with our speech-based service),
the analogy is straightforward:
Problem presented → student begins recording / begins speaking
The time lag between these two points can reasonably be considered a meaningful feature for uncertainty.
Fluency issues in L2 academic presentations: Linguistic, cognitive and psychological influences on pausing behaviour
- published in 2024 (4 citations)
This study, conducted in an EAP (English for Academic Purposes) class, explored where and why pauses occur in academic presentations by L2 (English as a foreign language) learners, and how they influence fluency. Unlike previous research that mainly emphasized quantitative measures (e.g., number/length of pauses), this work sought to explain the underlying causes—linguistic, cognitive, and psychological.
- (1) What are the types, positions, and frequencies of pauses?
- (2) What are the reasons for pauses?
-
Data
- 22 EAP students at an Australian university
- Each gave ~15-minute presentations
- A 1-minute segment was sampled for each; some 5-minute samples were also analyzed to test representativeness (t-test showed no significant difference)
-
Acoustic & Transcript Analysis
- Tools like Praat were used to measure the frequency, duration, and position of silent pauses and filled pauses (um, uh)
- Position categories: within-clause (MOC) vs. end-of-clause (EOC)
-
Stimulated Recall Interviews (SRI)
- Students re-watched their own presentation videos and were asked: “Why did you pause here?”
- 7 participants took part
- Researchers compared self-reports with observer interpretations
-
332 pauses total across 22 speakers
- 210 filled pauses, 122 silent pauses
- → Filled pauses more frequent
-
Distribution by position
- End-of-clause (EOC): 65.6%
- Mid-clause (MOC): 34.4%
-
Types of pauses
- Silent pause: complete break in sound, only breathing or silence
- Filled pause: hesitation sounds (um, uh, er, hmm, “like,” “so,” “you know”)
-
Planned pauses
- Typically at clause ends or after formulaic phrases (“first of all,” “generally speaking”)
- Functions: breathing, emphasis, giving processing time to listeners
-
Unplanned pauses
- Occurred during repetition, self-repair, lexical retrieval, planning, or unclassified cases
- Lexical retrieval/planning pauses often co-occurred with fillers like um/uh
The study identified overlapping linguistic, cognitive, and psychological causes for pauses:
-
Linguistic
- Pauses due to word search, pronunciation difficulty, or L1–L2 translation
- Self-monitoring and self-repair also triggered pauses
-
Cognitive
- Burden of recalling and organizing content (especially interpreting graphs) → more mid-clause pauses and repetitions
- Observers sometimes assumed “grammar checking,” but SRIs revealed it was often conceptual recall/restructuring instead
-
Psychological
- Anxiety/nervousness disrupted language and cognitive processing → increased silent/filled pauses and repetitions
- Conversely, confident speakers used clause-final pauses strategically (checking audience reaction, emphasis, giving processing time)
A single pause may have multiple overlapping causes (e.g., lexical search + anxiety). The same type of pause may stem from different reasons depending on the speaker. This shows how observer-only analysis can be misleading.
- Fluency is not just about speed or number of pauses. Effective presentations require simultaneous conceptual processing (cognitive), language production (linguistic), and psychological management.
- Clause-final pauses can be strategic and beneficial, serving discourse segmentation, emphasis, or audience processing time.
- Mid-clause silent pauses generally indicate processing difficulties, though causes vary by individual.
-
Differentiating pause types is insightful:
-
Silent pause
- Short, clause-final → marks discourse boundaries
- Long, mid-clause → failed recall, conceptual overload
-
Filled pause
- Short → minor planning strategy, not problematic
- Long → lexical difficulty, insufficient mastery to express concepts fluently
-
Planned pause
- Often for emphasis or breathing
-
Unplanned pause
- Common during recall, self-repair, or at ungrammatical break points
-
Prosodic Manifestations of Confidence and Uncertainty in Spoken Language — Structured Summary
- Published: 2008 (Interspeech/ICSLP, Brisbane)
- Author: Heather Pon-Barry (Harvard SEAS)
The paper asks where prosodic cues to confidence/uncertainty live in an utterance—are they concentrated on the target word/phrase that triggered the decision, or distributed in the surrounding context? It further contrasts self-reported certainty with perceived (listener-rated) certainty.
- Speakers: 20 native English speakers (14F/6M).
- Annotators: 5 native English raters (perceived certainty).
- Utterances: 600 total: 200 transit Q&A + 400 vocabulary sentences.
-
Boston public transit: fill-in-the-blank responses with constrained options (e.g., “Take the red line to the _ and get off at _”).
- Procedure included viewing the context alone, then context+options; a beep at 1500 ms cued reading aloud; speakers then self-rated certainty (1–5).
- Vocabulary: sentences completed by choosing 1 of 4 words from a small pool (incl. rare words to induce uncertainty). Same timing as above.
- Five raters judged perceived certainty (1–5) for all 600 utterances, presented without any textual context. Inter-rater agreement (κ) was modest and in line with prior affect work.
- Pitch (f0): min, max, mean, stdev, range, relative positions (min/max), absolute slope.
- Intensity (RMS): min, max, mean, stdev, relative positions (min/max).
- Temporal: total/percent silence, total duration, speaking duration (minus pauses), speaking rate.
- Normalization: all features z-scored per speaker (centered/standardized within speaker).
To localize cues, authors manually removed the target word region (including any immediately preceding pause) from each recording, producing separate context and target segments for parallel feature extraction.
- Perceived certainty exceeded self-reported certainty in 67% of utterances. This gap cautions that listeners often over-estimate a speaker’s confidence relative to the speaker’s own rating.
From Table 1 (correlations with mean perceived rating), the strongest effects are temporal:
- Total duration: −0.653 (longer ⇒ less certain)
- Total silence: −0.644 (more silence ⇒ less certain)
- Percent silence: −0.459
- Speaking duration: −0.515
-
Speaking rate: +0.134 (faster ⇒ slightly more certain)
Among f0/RMS: absolute f0 slope: +0.312 (steeper global slope associates with higher perceived certainty).
- Percent silence is much stronger in the target region (−0.568) than in context (−0.198): localized hesitations around the decision word flag uncertainty.
- Range f0 is stronger in context (−0.247) than target (≈0): broader pitch excursions in the surrounding phrase relate to uncertainty.
- Similar context-dominant patterns appear for min f0, max f0, f0 stdev, min RMS.
- Some features (e.g., absolute f0 slope, total duration, total silence) are best at the whole-utterance level; splitting doesn’t add predictive value for those.
- Temporal rhythm dominates: pauses, silence proportion, and overall length are the most reliable global indicators of perceived certainty.
-
Local vs. global cues:
- If you want to locate the uncertainty source, inspect target-region features—especially percent silence.
- If you’re classifying certainty for the whole utterance, global temporal features and absolute f0 slope are high-value.
- Perception ≠ self-report: Systems optimized only for perceived certainty risk missing actual uncertainty that speakers feel but listeners don’t detect.
- Read (non-spontaneous) speech was used to tightly control lexical content and repeat target words across certainty levels; generalization to spontaneous speech is future work.
- Additional planned work includes within-speaker analyses and feature-set comparisons for classification accuracy.
- ↓ Certainty: more/longer pauses (total/percent silence), longer utterances.
- ↑ Certainty (weak-moderate): steeper absolute f0 slope, slightly faster rate.
- Localization: percent silence peaks in target; f0 range patterns dominate in context.